
X-MAS CTF 2019 Logistics
Hello everyone! We are currently wrapping up the 2019 edition of X-MAS CTF. This year we have received some really positive feedback, and people seem to have had a lot of fun with our challenges. Amidst the ending preparations, I am taking a moment to talk about the whole logistics of the event, the things we’ve learned and what we could improve upon.
The network load
This year we have decided to double down with our competition by allocating a lot more time to server setup, challenge making and publicity. Thus, we already had about 2000 teams registered before the competition even started (which is about double the amount of last year’s edition). We have learned a lot since last year’s DDoS attack, and we have made sure that the servers can efortlessly withstand a constant load of a few hundred concurrent requests, with plenty of fallbacks in case we would actually get attacked again.
We had two Vultr High-Frequency Compute servers allocated for the contest, one with 8GB of RAM and 3 CPUs for our challenge server, and another one with 2GB with 1 CPU for our platform.
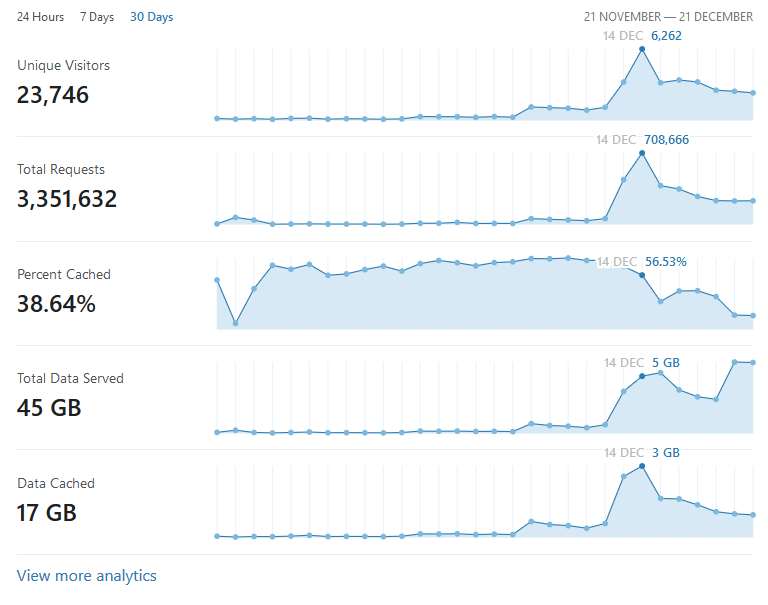
The actual competition load was about as follows:
- 250,000 daily requests for the entire week, peaking up at 700,000 requests during the week-end. Cloudflare has helped us a lot in caching and speeding up the platform considerably:
-
A median of 220 open sockets to our challenge server during the entire week.
-
4GB maximum RAM usage and 20% CPU load on our challenge server, which was running a total of 35 dockers.
-
400MB maximum RAM usage and 20% CPU load on our platform server, which was only running CTFx.
-
40GB total traffic on our challenge server, and 20GB total traffic on our platform server.
Our own setup
One of the most important things that we’ve done this year is to make our own platform according to our taste, by forking and understanding the codebase of an already-existing CTF platform, mellivora. This allowed us to finetune all aspects of the site in order to bring the experience we really wanted. This platform was also multiple times faster and less resource-heavy than CTFd, allowing us to run very comfortably on a server with 2GB of RAM, without ever experiencing any lag or delay, even in the most intense moments (such as the start of the CTF, when 400 teams have submitted flags in the first 5 minutes, the server still didn’t break a sweat: at 400 MB of RAM usage and 20% CPU load, things were running surprisingly smoothly).
Afterwards, we have dockerized all our on-line challenges, and made sure that each docker would be resource-limited to 100MB of RAM and only 0.1/3.0 CPUs. This way, in order to bring the server down, someone would have to attack all our dockers at the same time in full force, which isn’t something easy to do. For our web challenges we went with an nginx webserver, or nginx+gunicorn for python challenges. For pwn we chose xinetd, and for crypto/misc nc challenges we used socat, although it has been causing problems with sending special characters or printing messages (since socat requires a stdout flush for it to send data to the player).
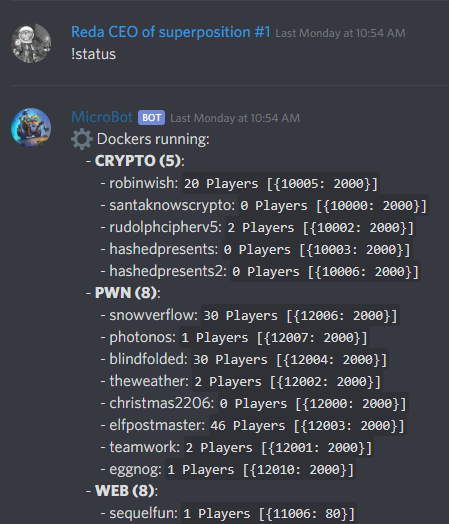
We’ve also built a Discord bot to start, stop and monitor all our challenge dockers, so that we could restart any challenge very quickly in case it went unresponsive. We have also implemented a public restart feature, where players could vote to automatically restart a challenge in case admins were offline, at 5AM for example. Sadly, not many participants knew of this feature, so we will try to make it more clear in the future. The bot was also able to show us how many players were connected to each challenge, which ended up being pretty useful:
Challenge preparation
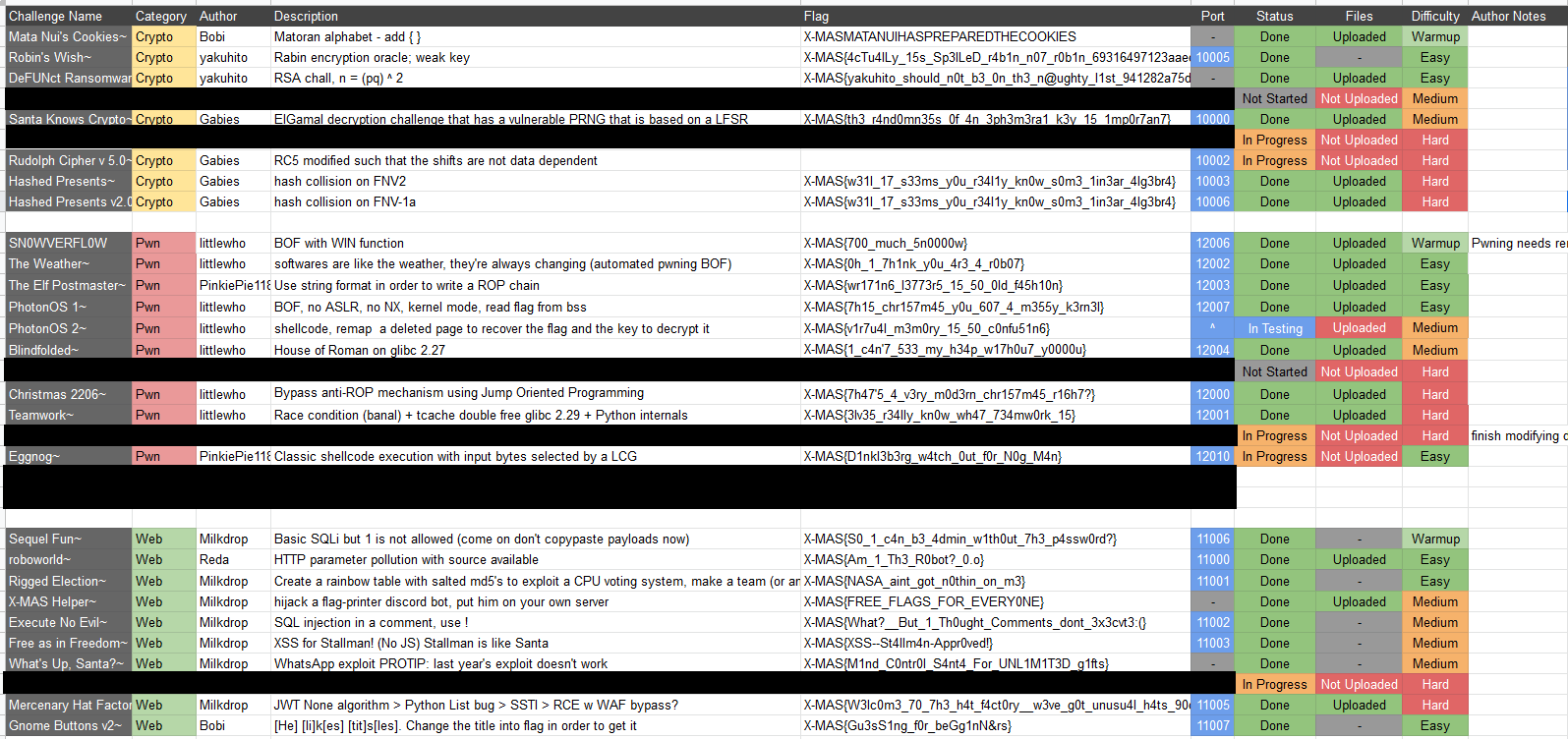
In order to store all our docker files or challenge data, we have created a git repository. This way, we would be able to do a simple git clone on our challenge server and fetch every file we need. We have also made a spreadsheet to efficiently note all challenge progress / ideas:
Final notes / improvements to do
This year we have tried to include some more experimental challenge categories, such as Emulation, Quantum or OSINT. These proved to be quite fun, so we will keep some of them in the upcoming editions. If we have new ideas, we might experiment with new ones as well.
Some notable improvements that we can make are an automatic integration of our spreadsheet into the CTFx platform (So we could automatically upload all challenge data with authors, descriptions, and file links). This year we had to allocate a few days to meticulously upload every single one of the 69 challenges, which included their flags, authors, descriptions and all other challenge data by hand. Having an automatic system for this process would be really handy.
Another improvement we could make is a better standardization of our challenge repository, since the public and setup layout ended up being pretty much useless and tiresome to follow. Next year we might also include an automatic !rebuild feature into our discord bot, so that we can quickly rebuild dockers and test our challenges without ever needing to SSH into the challenge server.